Abstract
Recent advances in biomedical applications have focused a lot of emphasis on the detection of what could be caused by cardiovascular disease (CVD). The electrocardiogram (ECG), which depicts the electrical activity of the heart, is the foundation for arrhythmia analysis. Different machine learning methods used on ECG datasets have demonstrated excellent performance in detecting arrhythmias. Nevertheless, feature extraction is necessary for machine learning algorithms. Modern deep learning techniques don’t require feature extraction because they learn all the parameters simultaneously, in contrast to these techniques. In this study, a 1D convolutional neural network (CNN) approach is presented and tested on the arrhythmia database of the Massachusetts Institute of Technology-Beth Israel Hospital (MIT-BIH). The proposed model, which only has three layers, attained an accuracy of 97.40%.
Keywords
electrocardiogram, ECG classification, arrhythmia detection, convolutional neural network, stochastic gradient descent, ECG, CNN, SGD
Abbreviations
CVD: cardiovascular disease; ECG: electrocardiogram; CNN: convolutional neural network; MIT-BIH: Massachusetts Institute of Technology-Beth Israel Hospital; KNN: K-nearest neighbor; SVM: support vector machine; LSTM: long short-term memory; AF: atrial fibrillation; RNN: recurrent neural network; WT: wavelet transform; DWT: discrete wavelet transform; SGD: stochastic gradient descent; AUC: area under curve; ROC: receiver operating characteristic
Introduction
As it is mentioned in the World Health Organization (WHO) reports, cardiovascular disease (CVD) is one of the major causes of death worldwide. Yearly, more than 30% of global deaths are caused by CVD. Besides, it is estimated that by 2035, more than 130 million adults will be suffering from CVDs [1]. Arrhythmias can be an indicator of underlying CVD. Arrhythmias are conditions whereby the heart beats with an irregular or abnormal rhythm. Early detection of arrhythmia holds immense importance because timely intervention and treatment can significantly enhance the chances of saving lives. It is estimated that between 6–12 million people will suffer from arrhythmia in the US by 2050. Therefore, detecting arrhythmia in the early stage is vital as with treatment, the lives of many can be saved. The solution for detecting arrhythmia in the early stage is continuous measurement of health parameters. Among physiological measurements, the electrocardiogram (ECG) is widely used for diagnosing arrhythmia. Continuous health parameter monitoring, particularly through ECG analysis and the integration of machine learning algorithms, is playing a pivotal role in transforming the landscape of CVD diagnosis and treatment, potentially saving countless lives in the process. In fact, the analysis of arrhythmia is mainly based on ECG [2–4]. Recently, machine learning algorithms have become important tools in diagnosing fatal diseases, such as CVD. Among machine learning methods, different algorithms have been used for the classification of arrhythmia, including K-nearest neighbor (KNN) [5], support vector machine (SVM) [6], fuzzy classifiers [7], feed-forward networks [8], long short-term memory (LSTM) [9], convolutional neural network (CNN), etc. Among these methods, different variations of CNN, including 1D CNN and 2D CNN, have shown great performance in arrhythmia detection based on ECG signals. Ullah et al. [2] developed two CNNs for arrhythmia detection based on ECG signals. One of their models is a 1D CNN with an accuracy of 97.38% on the Massachusetts Institute of Technology-Beth Israel Hospital (MIT-BIH) Arrhythmia Database, and the other, which is a 2D CNN model, achieved 99.02%, the highest accuracy among the researches so far. Also, Kiranyaz et al. [10] proposed a 1D CNN to categorize the data into five groups with an accuracy of 98.90% on the same dataset.
There are many different configurations of CNN models applied to arrhythmia detection. However, most of them are deep models consisting of several layers. Our work, on the other hand, is based on a shallow CNN model.
The detection of arrhythmias has significantly improved because of the combination of machine learning algorithms with continuous ECG monitoring in the diagnosis and treatment of CVD. Arrhythmias may now be recognised from ECG data using machine learning algorithms, which also include several classification strategies. These algorithms can recognise patterns and features in ECG signals, making it possible to classify arrhythmias accurately and automatically. In the detection of arrhythmias, machine learning techniques, particularly CNNs, have demonstrated outstanding accuracy. Examples are the accuracy values of 97.38% and 99.02% that Ullah et al. [2] published for the MIT-BIH Arrhythmia Database. Similar to this, Kiranyaz et al. [10] used a 1D CNN to obtain a high accuracy of 98.90%.
This paper takes a shallow 1D CNN model for an ECG dataset called the MIT-BIH Arrhythmia Database to categorize the signals into two main groups of normal and abnormal beats. As a version of end-to-end models adopted, there is no need for preprocessing the data. Also, there is no need for feature extraction, as in end-to-end models, all the parameters are trained simultaneously instead of step by step. Compared with other 1D CNN models trained on the same database, our model shows great performance.
The major contribution of this work is to replace the current deep neural network with a shallow neural network to achieve the same accuracy more effectively. In the realm of machine learning and artificial intelligence, the development of a shallow neural network that reaches the same degree of accuracy as deep neural networks is an impressive achievement. This strategy has the following implications and potential benefits: In comparison to deep neural networks, shallow neural networks often include fewer layers and parameters. Because of their simplicity, they may be simpler to comprehend, train, and use. Deep networks’ complicated designs make them difficult to develop and optimise. A shallow network might make the process of creating a model easier and lessen the need for in-depth hyperparameter tuning.
The rest of the paper is organized as follows: Section 2 is an introduction to ECG and then arrhythmia. Then, the MIT-BIH Arrhythmia Database is introduced. In the last part of section 2, we have a review of previous work in the sphere of arrhythmia deception based on ECG signals. Section 3 presents a thorough description of CNNs and how they work. Section 4 is dedicated to classification, including optimization and model performance. Different methods of model evaluation are presented. After that, we have the architecture of the model in section 5. In this section, we explain how we developed our model and how it works. Section 5 gives conclusions to summarise the study.
Characterisation of ECG and Arrhythmia
ECG
In cardiology, ECG is a crucial diagnostic tool. In addition to detecting CVD, ECG signals, as depicted in the figure (Figure 1), can be utilised to evaluate breathing patterns and any kind of mental stress. The electrical activity of the heart, which coordinates the synchronised contraction of its chambers and enables effective blood circulation throughout the body, produces the ECG signal. The complicated processes involving the ion movement within cardiac muscle cells give birth to this electrical activity. The foundation of the current algorithms for automated ECG diagnosis of cardiac arrhythmia is the evaluation of the morphological properties of a single or limited number of QRS complexes or beats. An ECG is a record of the heart’s electrical activity, and an ECG signal captures that activity. These signals are related to numerous complex and interrelated mechanical, electrical, and chemical processes in the heart. They provide helpful knowledge on the functioning of the circulatory and neurological systems, as well as the heart. ECG can be used to evaluate breathing patterns as well. It can assist in tracking respiratory rate and locating respiratory conditions that might have an impact on the heart when paired with other data. Additionally, ECG is a useful tool for stress testing and determining how the heart reacts to psychological stressors since it can identify variations in heart rate and rhythm linked to mental stress [11].
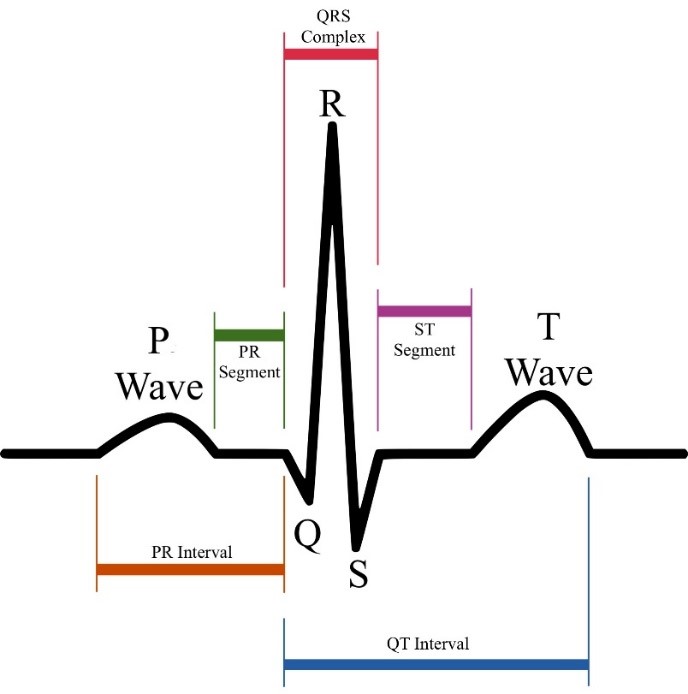 Figure 1: Electrocardiogram (ECG) signal.
Figure 1: Electrocardiogram (ECG) signal.
The heart muscle is electrically activated as a result of the ECG signal. The stimulation causes the heart’s atria and ventricles to constrict, which in turn encourages heart muscle cells to do the same. Muscular contraction causes blood to start flowing through the organs. As a result of the electrical stimulation spreading throughout the heart muscle, a depolarization wave is produced in the cardiac cells. This depolarization wave was generated by the fast sodium ion fluctuation. Following the depolarization wave, a phase known as the re-polarization phase, the heart muscle cells return to their resting state. Ion fluctuations within the cells are what cause heart muscle cells to depolarize and repolarize. An electrical current is generated by the movement of ions within the cardiac muscle cells, and this electrical current, in turn, generates an electromagnetic field around the heart.
At two different bodily regions, ECG signals are captured as variations in electric potentials. The voltage that was recorded between the two places and this variation are consistent. This voltage is a representation of the ECG signal’s strength as it was recorded in the two-electrode setup. The two-electrode configuration is known as an ECG lead. In this setup, one electrode functions as an active measurement unit and the other electrode as the resource. The voltage change of two electrodes throughout this period represents the course of the ECG signal. The signal that is captured on paper or electronic equipment is referred to as an “ECG” in this context. By studying ECG data, we can gain important knowledge on the mechanical, anatomical, and electrical elements of the heart. The ECG signals are made up of the P wave, which represents the depolarization of the atria, the QRS complex, which indicates the contraction of the ventricles due to depolarization, and the T wave, which represents the repolarization of the ventricles.
Arrhythmia
Arrhythmia is one of the most common forms of CVD, which results in irregular heartbeats. A slow, rapid, or erratic beat can all be considered irregular. Arrhythmia can range widely, which means it may just cause minor pain or, in rare circumstances, result in death. While some arrhythmia cases go undetected, the more severe ones can make it difficult to breathe or cause chest pain. Although the majority of arrhythmias are not dangerous, some of them can cause heart attacks or strokes. The type of arrhythmia that occurs most frequently is atrial fibrillation (AF). Between 6 and 12 million people in the US are predicted to have AF by the year 2050 [12].
The use of wearables to continuously monitor patients is becoming more popular as a result of technological advancements. Therefore, automatic arrhythmia detection methods are necessary. There are a few steps in the machine learning-based arrhythmia detection process that must be finished before the model can identify the type of irregularity and classify it after the signal has been cleaned of noise and distortions. Arrhythmia is a disorder of the heart’s rhythm. Either a single irregular heartbeat or a series of them is feasible.
Several machine learning techniques have become well-known in the field of arrhythmia identification due to their efficacy. Three standouts are as follows:
Support vector machines (SVM): In detecting arrhythmias, SVM has shown outstanding performance accuracy. Its main advantage is its prowess in nonlinear, high-dimensional recognition tasks, which are frequently encountered in the processing of challenging physiological data. Even with small sample sets, SVM can accurately categorise arrhythmias, making it a useful diagnostic tool.
Neural networks: For the identification of arrhythmias, neural networks, particularly deep learning architectures, have been frequently used. The automatic classification of arrhythmias benefits from the ability of CNNs and recurrent neural networks (RNNs) to learn complex patterns within ECG data.
Fuzzy classifiers: Arrhythmia detection can be done in a different way with fuzzy logic-based classifiers. They are able to deal with the data’s uncertainty and imprecision, which are common in medical contexts. When it comes to dealing with ambiguous or borderline cases of arrhythmia, fuzzy classifiers can be especially helpful.
SVM, neural networks, and fuzzy classifiers, among other machine learning tools, are crucial for turning raw ECG data into insights that can be put to use. Early detection of arrhythmias is essential for patient treatment since these algorithms can identify tiny patterns and aberrations that could be invisible to the human eye.
In conclusion, the requirement for automatic arrhythmia detection techniques is becoming more critical as wearable technology develops. SVM, neural networks, and fuzzy classifiers are a few examples of machine learning algorithms that provide strong tools for precisely recognising and categorising arrhythmias. In the area of heart health, these techniques help to improve patient monitoring, early intervention, and healthcare outcomes.
MIT-BIH Arrhythmia Database
The MIT-BIH Arrhythmia Database was created from more than 4000 ECG records that the Beth Israel Hospital Arrhythmia Laboratory registered between 1975 and 1979. The database has 48 records overall, each lasting a little longer than 30 min; 23 records were chosen at random, while the remaining 25 were chosen from the same group. Almost 60% of the data is gathered from patients.
The MIT-BIH database has been utilized for most published studies because it is the most representative database for arrhythmia.
Previous work
Utilizing machine learning techniques, the procedure for identifying arrhythmia from ECG signals involves sequential steps of pre-processing, feature extraction, feature selection, and classification. Nevertheless, the progression of end-to-end algorithms facilitated by deep learning methodologies has transformed ECG-based arrhythmia diagnosis. This evolution eliminates the necessity for intricate feature engineering, as end-to-end models concurrently learn all parameters rather than individually. There are numerous strategies documented in the literature for the pre-processing step of ECG signal noise elimination, including average and median filters, bandpass filtering, empirical mode decomposition (EMD) [13], independent component analysis (ICA) [14], adaptive filters [15], adaptive Fourier decomposition [16], threshold method for high-frequency noise detection [17], Kalman filters [18], neural networks [19], convolutional neural networks (CNNs) [20], wavelet transform (WT) [13, 16, 18], and a combination of neural networks with the discrete wavelet transform (DWT) [21].
For ECG feature extraction, several techniques like Hermite coefficients [22], high-order statistics (HOS) features [23], wavelet features [24–27], and waveform shape features [28, 29] have been applied.
Different machine learning methods have been used for the classification of arrhythmia. Among these methods, the 2D CNN proposed by Ullah et al. [2] achieved the highest accuracy. Besides, 1D CNN methods showed great performance in arrhythmia detection. The 1D CNN model proposed by Kiranyaz et al. [10] achieved second place with 98.90% accuracy on the test set. They trained the model using patient-specific training data.
Deep 1D CNN was able to classify each sample in 0.015 seconds while achieving an overall recognition accuracy of 91.33% [30].
Using enhanced expectation-maximization (EM) and Gaussian mixture model (GMM), Ghorbani Afkhami et al. [31] reported a technique for detecting arrhythmias. They achieved a classification accuracy for arrhythmias of 99.7%.
Kaur et al. [32] used WT for ECG-based arrhythmia detection and achieved a sensitivity of 99.85% and positive predictivity of 99.92% (Table 1).
| References | Year | Method | Performance measure |
| Daamouche et al. [6] | 2012 | SVM | Sensitivity: 91.75%; specificity: 96.14% |
| Homaeinezhad et al. [33] | 2012 | Neuro SVM-KNN fusion classification | Accuracy: 98.20% |
| Kutlu et al. [5] | 2012 | KNN | Sensitivity: 90%; specificity: 98% |
| Rai et al. [8] | 2013 | MLP, feed-forward network, back-propagation | Sensitivity: 90%; specificity: 96% |
| Martis et al. [34] | 2013 | NN, SVM | Accuracy: 93.00% |
| Javadi et al. [35] | 2013 | Negative correlation neural learning | Accuracy: 96.02%; sensitivity: 92.27%; specificity: 98.01% |
| Vafaie et al. [7] | 2014 | Fuzzy classifier; genetic algorithm | Genetic algorithm accuracy: 98.67%; fuzzy classifier accuracy: 93.34% |
| Zhang et al. [36] | 2014 | Multi-lead fused classification scheme | Accuracy:87.88% |
| Zubair et al. [37] | 2016 | 1D CNN | Accuracy: 92.60% |
| Al Rahhal et al. [38] | 2016 | DNN | Accuracy: 98% |
| Kiranyaz et al. [10] | 2016 | 1D CNN | Accuracy: 98.90%; sensitivity: 95.90% |
| Rangappa et al. [39] | 2018 | KNN | Accuracy: 98.40% |
| Alfaras et al. [40] | 2019 | Machine learning-based echo state networks | Sensitivity: 92.7%; precision: 86.1% |
| Rajkumar et al. [41] | 2019 | 1D CNN | Accuracy: 90.00% |
| Izci et al. [42] | 2019 | 2D CNN | Accuracy: 97.42% |
| Tuncer et al. [43] | 2019 | hexadecimal local patterns (HLPs) and discrete wavelet transform (DWT) | Accuracy: 99.7% |
| Zhang et al. [9] | 2021 | LSTM, CNN | Accuracy: 95.28% |
| Ullah et al. [2] | 2021 | 1D CNN, 2D CNN | 1D CNN accuracy: 97.38%; 2D CNN accuracy: 99.02% |
Table 1: Strategies documented in the literature for the pre-processing step of ECG signal noise elimination.
Among different methods, CNNs show great potential in achieving high accuracies.
Convolutional Neural Network
Convolutional neural networks (CNNs) are a specialised class of artificial neural networks carefully created for handling grid-like input structures. Time series data, which may be thought of as a 1D grid, or photographs, which are effectively 2D grids made up of pixels, might both be examples of these data grids, as explained by Goodfellow et al. [44]. In essence, the input layer, one or more hidden layers, and the output layer are the three basic building blocks of CNNs and other feedforward neural networks.
The application of a mathematical procedure known as convolution, at least once within each of their layers, is the distinguishing feature that gives CNNs their name. Similar to how neurons in the human brain react when they come into contact with a certain stimulus, this convolution activity has a purpose. CNNs are particularly well-suited for tasks involving grid-like structures because they are highly effective at recognising patterns and features within the input data by applying convolution. In the figure below (Figure 2), a convolution layer has been depicted for better understanding.
 Figure 2: A convolution operation.
Figure 2: A convolution operation.
Every CNN also includes a layer known as pooling in addition to convolution. There are several different pooling techniques, with “max pooling” being one of the most popular. In max pooling, the network retains the maximum value while condensing the data within a rectangle neighbourhood. In order to improve the computational efficiency of the model, this pooling layer is crucial in lowering the spatial dimensions of the data. In essence, pooling aids in gathering the most important data while omitting irrelevant details, which is very useful in image processing tasks. The figure (Figure 3) depicts the behaviour of a max pooling layer.
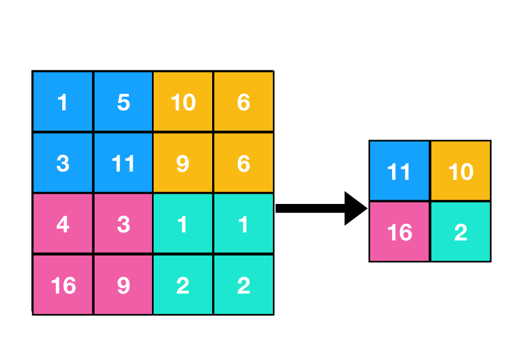 Figure 3: A max pooling layer.
Figure 3: A max pooling layer.
The completely connected layer, which is a feature shared by all CNN models, is another essential element. These completely linked layers, which are frequently placed before the output layer, act as a link between the retrieved features and the ultimate prediction or classification goal. They give the network the ability to understand complex connections and relationships between the data acquired by convolution and pooling layers, enabling more precise and complex predictions.
CNNs, a potent and crucial tool in the field of deep learning, are created expressly to succeed in problems involving structured data grids, such as those involving images and time series data. In a variety of applications, from image recognition to natural language processing and beyond, they are able to extract meaningful features, reduce computational complexity, and provide exceptional performance because of their ability to perform convolutions, pooling operations, and use fully connected layers.
Activation function
In neural networks, each neuron calculates the weighted sum of its inputs, applies the activation function, a nonlinear function, and then outputs the outcome to the next layer. The activation function is a kind of operation acting on the inputs. The activation function ReLU is defined as g (z) = max{0,z}. This represents applying the ReLU yields a nonlinear transformation.
Another commonly used activation function is sigmoid. The sigmoid function is defined as 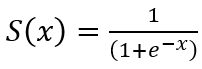 . Softmax is defined as
. Softmax is defined as 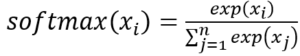 .
.
Dropout
Typically, we are curious about how well an algorithm performs on unobserved data. We divided the data into a train set and a test set as a result. We have two types of errors when we split the dataset into the training and test sets. Overfitting occurs when there is a difference between the training and the test error. We employ dropout, which randomly omits some connections between the neurons in the model, to prevent overfitting in our model. To lessen overfitting, a regularisation technique called dropout is used. During each training iteration, it randomly deactivates (drops out) a portion of the neural network’s neurons or connections. The dropout procedure generates noise and forces the model to make predictions using a more reliable and distributed collection of attributes. Dropout thereby enhances the model’s generalisation capability by preventing the model from becoming highly specialised in fitting the training data.
Classification
One of the most common machine learning tasks, classification, involves classifying inputs into the appropriate groups. A matrix known as the design matrix serves as the data representation in machine learning models. The design matrix has different examples in each row, and each column represents a different characteristic. The weight matrix is a different matrix we have that has the parameters. The parameters change to new values as the models are being trained. We should use optimisation techniques to minimise the cost function when training the model. The method that determines the gradient of the cost function with respect to the parameters and subsequently modifies the parameters is called back-propagation.
Cost function
In order to train the model, we optimise the cost function. The model’s weights are changed as the cost function is minimised. Machine learning model training’s core goal is to optimise the cost function by changing the model’s weights. As a result, the model can successfully carry out the desired task, whether it be classification, regression, or another machine learning task. This process enables the model to learn from the training data and make correct predictions on fresh, unknown data.
Binary cross-entropy, also known as log loss, is a cost function applied in binary classification problems. It is defined as 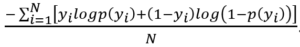 .
.
Optimisation
There are two types of errors in machine learning issues. The mistake determined on the training set is known as the training error. The term “generalisation error” or “test error” refers to the error determined by unobserved data, namely the test set. The objective of machine learning problems is to lower test and training errors. Optimisation techniques are used to discover the best values for the model’s parameters and minimise the cost function. Machine learning models are frequently trained using gradient-based optimisation techniques like stochastic gradient descent (SGD), Adam, or RMSprop. These algorithms repeatedly change the parameters of the model in a way that lowers the cost function.
- Stochastic gradient descent algorithm
Stochastic gradient descent (SGD) is an iterative optimisation technique for objective functions that typically exhibits smoothness features. One of the most significant algorithms in deep learning and machine learning is SGD. Due to its efficiency and effectiveness in minimising objective functions, SGD is a crucial optimisation process in machine learning and deep learning. It is a foundational technique for training a broad variety of machine learning models, especially in the era of deep learning, due to its stochastic character, which enables it to handle enormous datasets and complex models quickly.
Algorithm) SGD update at training iteration r [44]
Require: Learning rate ϵr
Require: Initial parameter θ
while stopping criterion not met do
Sample a minibatch of n examples from the training set {x(1),…x(m)} with corresponding targets y(i).
Compute gradient estimate: 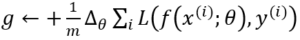
Apply update: θ←θ-ϵg
end while
Model performance
To measure the ability of an algorithm, we must use a performance measure. For the classification task, plenty of statistical measurements are used.
Accuracy is defined as the ratio of the correct predictions to the total amount of data. Most of the ECG-related studies prefer accuracy as the success measure. Accuracy is defined as below: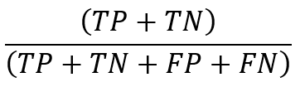
Recall, which is also known as sensitivity, refers to the percentage of pertinent instances that were successfully recovered. Recall specifically determines how many of the samples that are actually positive are anticipated to be positive. It is just the ratio of samples that were positively predicted to all samples that were actually positive. The following formalizes recall:
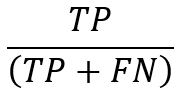
Precision is the percentage of pertinent occurrences among the retrieved instances, often known as the positive predictive value. Simply put, it is the percentage of real positives within the overall number of favorably predicted samples. Here is how precision is defined:
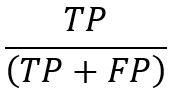
For each accessible category, a model’s ability to predict true negatives is measured by the statistic known as specificity. The following formalizes specificity:
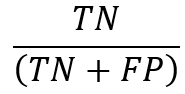
- Area under curve (AUC) (or receiver operating characteristic (ROC))
The true positive rate or sensitivity is shown against the false positive rate, which is the ratio of false positives to the total number of negative samples at different settings. This is known as the receiver operating characteristic (ROC) curve. Two places are created within the ROC by the diagonal line. In contrast to the area beneath the line, which reflects results that are worse than a random forecast, the area above the line displays positive model results.
Results
For building a machine learning model, three things are required: a dataset for training and then validating, a cost function, and an optimization algorithm.
To classify the heartbeats into normal/abnormal classes, we applied a 1D shallow CNN model consisting of one convolution layer, one fully connected layer, and a dense layer. After training the model for one hundred epochs, the results are displayed in the table below (Table 2). The model could separate the normal from abnormal cases with an accuracy of 97.4%. The architecture of the model has been drawn in the figure (Figure 4). Also, the area under curve (AUC) curve of the model has been drawn in the figure (Figure 5).
| Train | Test |
| AUC | 0.998 | 0.993 |
| Accuracy | 0.985 | 0.974 |
| Specificity | 0.981 | 0.980 |
| Precision | 0.987 | 0.957 |
| Recall | 0.981 | 0.961 |
Table 2: Results after training the model for one hundred epochs.
 Figure 4: The architecture of the model.
Figure 4: The architecture of the model.
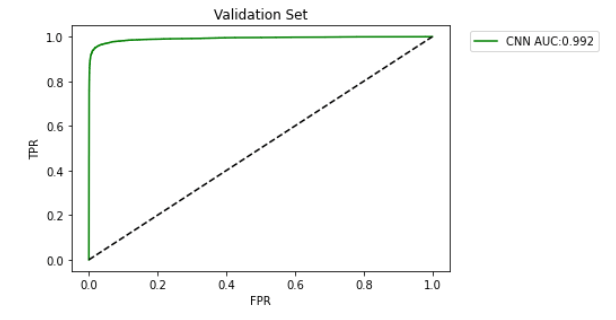 Figure 5: The area under curve (AUC) curve.
Figure 5: The area under curve (AUC) curve.
Conclusion
Information about the heart’s electrical activity is present in the ECG signal, which is useful for diagnosing heart conditions. An algorithm for ECG-based arrhythmia detection was put out in this study. The results demonstrate the model’s strong performance when compared to other efforts. The creation of an effective ECG-based arrhythmia detection algorithm is an important achievement with applications in healthcare and medical diagnosis. The success of this algorithm opens the door to a number of potential future applications with concise shallow neural networks, including the incorporation of automated arrhythmia detection into medical devices, wearable technology, telemedicine platforms, and electronic health record systems.
Acknowledgements
The first author is grateful for the PhD studentship support from the University of the West of England and August International Ltd.
References
- Belaid B, Slimane Z-E H. A new design of real-time monitoring and spectral analysis of EEG and ECG signals for epileptic seizure detection. International Journal of Medical Engineering and Informatics. 2021;13(4): 269-78.
- Ullah A, Rehman SU, Tu S, et al. A Hybrid Deep CNN Model for Abnormal Arrhythmia Detection Based on Cardiac ECG Signal. Sensors (Basel). 2021;21(3):951.
- Salam KA, Srilakshmi G. An algorithm for ECG analysis of arrhythmia detection. 2015 IEEE International Conference on Electrical, Computer and Communication Technologies. 2015;1-6.
- Xie L, Li Z, Zhou Y, et al. Computational Diagnostic Techniques for Electrocardiogram Signal Analysis. Sensors (Basel). 2020;20(21):6318.
- Kutlu Y, Kuntalp D. Feature extraction for ECG heartbeats using higher order statistics of WPD coefficients. Comput Methods Programs Biomed. 2012;105(3):257-67.
- Daamouche A, Hamami L, Alajlan N, et al. A wavelet optimization approach for ECG signal classification. Biomed Signal Process Control. 2012;7(4):342-49.
- Vafaie M, Ataei M, Koofigar HR. Heart diseases prediction based on ECG signals’ classification using a genetic-fuzzy system and dynamical model of ECG signals. Biomed Signal Process Control. 2014;14:291-96.
- Rai HM, Trivedi A, Shukla S. ECG signal processing for abnormalities detection using multi-resolution wavelet transform and Artificial Neural Network classifier. Measurement. 2013;46(9): 3238-246.
- Zhang X, Li J, Cai Z, et al. Over-fitting suppression training strategies for deep learning-based atrial fibrillation detection. Med Biol Eng Comput. 2021;59(1):165-73.
- Kiranyaz S, Ince T, Gabbouj M. Real-Time Patient-Specific ECG Classification by 1-D Convolutional Neural Networks. IEEE Trans Biomed Eng. 2016;63(3):664-75.
- Gacek A, Pedrycz W. ECG Signal Processing, Classification and Interpretation. Springer; 2012.
- Lippi G, Sanchis-Gomar F, Cervellin G. Global epidemiology of atrial fibrillation: An increasing epidemic and public health challenge. Int J Stroke. 2021;16(2):217-21.
- Lee J, McManus DD, Merchant S, et al. Automatic motion and noise artifact detection in Holter ECG data using empirical mode decomposition and statistical approaches. IEEE Trans Biomed Eng. 2012;59(6):1499-1506.
- Kuzilek J, Kremen V, Soucek F, et al. Independent component analysis and decision trees for ECG holter recording de-noising. PLoS One. 2014;9(6):e98450.
- Lu G, Brittain JS, Holland P, et al. Removing ECG noise from surface EMG signals using adaptive filtering. Neurosci Lett. 2009;462(1):14-19.
- Wang Z, Wong CM, da Cruz JN, et al. Muscle and electrode motion artifacts reduction in ECG using adaptive Fourier decomposition. 2014 IEEE International Conference on Systems, Man, and Cybernetics. 2014; 1456-461.
- Le K, EftestØl T, Engan K, et al. High Frequency Noise Detection and Handling in ECG Signals. 2018 26th European Signal Processing Conference. 2018;46-50.
- Panigrahy D, Sahu PK. Extended Kalman smoother with differential evolution technique for denoising of ECG signal. Australas Phys Eng Sci Med. 2016;39(3):783-95.
- Rodrigues R, Couto P. A Neural Network Approach to ECG Denoising. arXiv. 2012.
- Arsene CTC, Hankins R, Yin H. Deep Learning Models for Denoising ECG Signals. 2019 27th European Signal Processing Conference. 2019;1-5.
- Kærgaard K, Jensen SH, Puthusserypady S. A comprehensive performance analysis of EEMD-BLMS and DWT-NN hybrid algorithms for ECG denoising. Biomed Signal Process Control. 2016;25:178-87.
- Ince T, Kiranyaz S, Gabbouj M. A generic and robust system for automated patient-specific classification of ECG signals. IEEE Trans Biomed Eng. 2009;56(5):1415-426.
- Osowski S, Hoai LT, Markiewicz T. Support vector machine-based expert system for reliable heartbeat recognition. IEEE Trans Biomed Eng. 2004;51(4):582-89.
- Ye C, Kumar BV, Coimbra MT. Heartbeat classification using morphological and dynamic features of ECG signals. IEEE Trans Biomed Eng. 2012;59(10):2930-941.
- de Lannoy G, Francois D, Delbeke J, et al. Weighted conditional random fields for supervised interpatient heartbeat classification. IEEE Trans Biomed Eng. 2012;59(1):241-47.
- de Oliveira LS, Andreão RV, Sarcinelli-Filho M. Premature Ventricular beat classification using a dynamic Bayesian Network. Annu Int Conf IEEE Eng Med Biol Soc 2011;2011:4984-987.
- Adam A, Shapiai MI, Tumari MZ, et al. Feature selection and classifier parameters estimation for EEG signals peak detection using particle swarm optimization. ScientificWorldJournal. 2014;2014:973063.
- Zhang Z, Dong J, Luo X, et al. Heartbeat classification using disease-specific feature selection. Comput Biol Med. 2014;46:79-89.
- Huang HF, Hu GS, Zhu L. Sparse representation-based heartbeat classification using independent component analysis. J Med Syst. 2012;36(3):1235-247.
- Yıldırım Ö, Pławiak P, Tan RS, et al. Arrhythmia detection using deep convolutional neural network with long duration ECG signals. Comput Biol Med. 2018;102:411-20.
- Ghorbani Afkhami R, Azarnia G, Tinati MA. Cardiac arrhythmia classification using statistical and mixture modeling features of ECG signals. Pattern Recogn Lett. 2016;70:45-51.
- Kaur I, Rajni R, Marwaha A. Ecg Signal Analysis and Arrhythmia Detection Using Wavelet Transform. J Inst Eng India Ser B. 2016;97(4): 499–507.
- Homaeinezhad M, Atyabi S, Tavakkoli E, et al. ECG arrhythmia recognition via a neuro-SVM–KNN hybrid classifier with virtual QRS image-based geometrical features. Expert Syst Appl. 2012;39(2):2047-058.
- Martis RJ, Acharya UR, Mandana KM, et al. Cardiac decision making using higher order spectra. Biomed Signal Process Control. 2013;8(2):193–203.
- Javadi M, Arani SAAA, Sajedin A, et al. Classification of ECG arrhythmia by a modular neural network based on mixture of Experts and negatively correlated learning. Biomed Signal Process Control. 2013;8(3):289-96.
- Zhang Z, Luo X. Heartbeat classification using decision level fusion. Biomed Eng Lett. 2014;4(4):388-95.
- Zubair M, Kim J, Yoon Changwoo. An Automated ECG Beat Classification System Using Convolutional Neural Networks. 2016 6th International Conference on IT Convergence and Security. 2016;1-5.
- Al Rahhal MM, Bazi Y, AlHichri H, et al. Deep learning approach for active classification of electrocardiogram signals. Inf Sci. 2016;345:340-54.
- Rangappa VG, Prasad SVAV, Agarwal A. Classification of Cardiac Arrhythmia stages using Hybrid Features Extraction with K-Nearest Neighbour classifier of ECG Signals. Int J Intell Eng Syst. 2018;11:21-32.
- Alfaras M, Soriano MC, Ortín S. A fast machine learning model for ECG-based heartbeat classification and arrhythmia detection. Front Phys. 2019;7:103.
- Rajkumar A, Ganesan M, Lavanya R. Arrhythmia classification on ECG using Deep Learning. 2019 5th International Conference on Advanced Computing & Communication Systems. 2019;365-69.
- Izci E, Ozdemir MA, Degirmenci M, et al. Cardiac Arrhythmia Detection from 2D ECG Images by Using Deep Learning Technique. 2019 Medical Technologies Congress. 2019;1-4.
- Tuncer T, Dogan S, Pławiak P, et al. Automated arrhythmia detection using novel hexadecimal local pattern and multilevel wavelet transform with ECG signals. Knowl-Based Syst. 2019;186:104923.
- Goodfellow I, Bengio Y, Courville A. Deep Learning. MIT Press;2016.
